
Introduction [00:00:05]

Alessio Fanelli: Hello everyone, and welcome back to another Latent Space Lightning Pod. This is Alessio, Partner and CTO at Decibel.
Swyx: And I'm Swyx, founder of Smol AI. Today, we are joined by Mitesh and Thomas from Positron AI. Welcome.
Mitesh Agarwal & Thomas Sohmers: Thanks for having us. Great to be here.
Swyx: Special shout-out to Maxime from DFJ for putting us in touch.
The Founding Story of Positron AI [00:00:28]
Swyx: Both of you have a background in some of the top chip companies in the world, mostly Lambda Labs, but also a little bit of Groq. How do you find your way to Positron? What's the founding thesis and the founding story?
Thomas's Journey to Positron [00:00:44]
Thomas Sohmers: I got my start in the semiconductor industry back in 2013. I started my first company, Rex Computing, which was focused on DSP for mobile base station workloads. I started that after receiving the Thiel Fellowship. I was 17 with the crazy idea of starting a semiconductor startup. Thankfully, I was able to convince some folks to join me, and we raised $2 million and ended up taping out our first chip when I was 19. We had leading silicon for that time for that signal processing workload. Sadly, it didn't get commercial success, but it was an amazing experience to be able to produce silicon from scratch.
After that, I worked on a couple of cryptocurrency ASICs before joining a French startup called Lambda. I was Principal Hardware Architect there and built out the first couple of data centers for Lambda Cloud. That's where I had the opportunity to work with Mitesh. I actually introduced him to Lambda, which led to him joining before I was an employee there. Mitesh and I have been housemates and very good friends for over a decade.
After my stint at Lambda, I wanted to get back into actual semiconductors, so I joined Groq. I was there as Director of Technology Strategy for two years. Then in early 2023, I decided to leave and start Positron. I originally tried to recruit Mitesh to be CEO of Positron back then, but he was growing Lambda crazily at that time. So, I was CEO of Positron for the first 18 months or so and finally was able to bring Mitesh over. He joined at the beginning of this year as CEO, and I'm now CTO.
Mitesh's Journey to Positron [00:02:38]
Mitesh Agarwal: My story is simpler. Thomas introduced me to Lambda Labs. I loved working with Stephen and Michael, the Balaban brothers. I grew the company from $0 in revenue to well over half a billion in ARR. I was an early employee, number five, so I did all types of roles: engineering, sales, support, you name it. I ended up as COO and Head of Cloud. My main focus was building out the cloud at Lambda—revenue, operations, data center megawatts, vendor relationships, and engineering headcount.
Lambda is still growing massively, and I have great admiration for what they're building. The two reasons I left were:
-
I could see a little bit around the corner at Lambda. Working with frontier model labs and enterprise companies, I was seeing how model architectures were growing and the requirements around memory architecture, capacity, and bandwidth. I wanted to contribute to the underlying technology stack.
-
My background is in chemical engineering, so I studied fabrication and really wanted to get back into the silicon space.
I was talking to Thomas in December after my first kid was born in November. He said, "Well, you already had one major change, why not make it two major changes in your life?" So I decided to join in January 2024.
Why Hardware Over Software? [00:04:35]

Alessio Fanelli: Were you guys thinking about sticking to the software side at all, or did you see that as a local maxima and that the hardware had to be rebuilt?
Thomas Sohmers: For me, I've always been a hardware guy. I started tinkering with electronics when I was five or six years old. While I programmed a bit as a kid, I was always more interested in physical things that could actually burn or blow up in my face.
The Hardware Bottleneck for AI [00:05:17]
Thomas Sohmers: Looking at the application space, I'm a huge believer in the future growth of this industry. The biggest limiting factor for that being distributed at scale is the cost, both in dollars and power, for deploying these applications. The future is here, it's just not evenly distributed. The limiting factor for that is the cost and power perspective.
So, starting the company was focused on how we can get the best performance-per-dollar and performance-per-watt for these workloads. With my experience from DSP work to my time at Lambda, I saw that the way the whole industry had been going for the decade before ChatGPT was not optimizing for the right things for what Transformer inference really needed. The underlying algorithms have very different hardware requirements than what was needed for CNNs and the first wave of modern machine learning.
Everyone else was focusing on having more and more FLOPS, when memory bandwidth and memory capacity were the real bottlenecks. Everyone that has been focusing on that is completely missing these neglected parts of computer architecture and processor design that I got exposed to through my career.
Mitesh Agarwal: For me, it's the bitter lesson: compute is the driving force for a lot of modern improvements. This is not to say software is at a local maxima; it's more about our backgrounds and what we are good at. Many people are doing amazing work on model improvements. But the more compute you can provide, the better it is for people working on software to drive more utilization and intelligence. So for me, it's still about how you can just drive more compute in the world, from FLOPS, memory, and deployment perspectives.
Positron's Unique Approach [00:07:43]

Alessio Fanelli: Can you talk about what you guys are doing that is unique, and maybe contrast that with NVIDIA, AMD, Groq, Cerebras, and the long tail of other GPU alternatives?
Thomas Sohmers: I'll share my screen to cover a couple of things. This is a roofline plot, which is an abstracted way to look at one of the key differences between convolutional neural networks (CNNs) and Transformers, specifically at inference time. It shows operational or arithmetic intensity as a fraction of performance.
In the top right corner is an example of a compute-bound problem: matrix-matrix multiplication for a CNN. Depending on the parameters, this can be anywhere from 500 to 1,000 FLOPS for every byte that needs to be moved. On the other side of this chart, you have the case of a Transformer. When you're doing attention, or fundamentally doing matrix-vector multiplication rather than matrix-matrix multiplication, you are now completely memory-bound. For every step in the sequence, you're having a one-to-one ratio of FLOPS to bytes that have to be moved.
The big realization at the beginning of Positron was that this looks a lot like doing QAM256 in a mobile base station for LTE. The systems built for that, namely FPGAs and specialized DSP chips, have an extreme focus on the memory system and the ability to saturate the DSP compute elements at that one-to-one memory-to-compute ratio.
If you look at traditional big iron compute systems, the last major compute platform that had that balance of memory-to-compute ratio was the Cray-2 supercomputer. We're pushing 40-plus years of computing development that has been focused on just providing more raw math compute capability while not balancing that by having memory scale in the same way.
This was the key thing we saw: everyone had been optimizing for the CNN portion of the workload. When you're doing training for Transformers, you're also in this very compute-bound case because you already have the full sequence of tokens. But it is this particular case of Transformer inference that is massively memory-bound.
Positron's Memory and Performance Advantage [00:12:52]
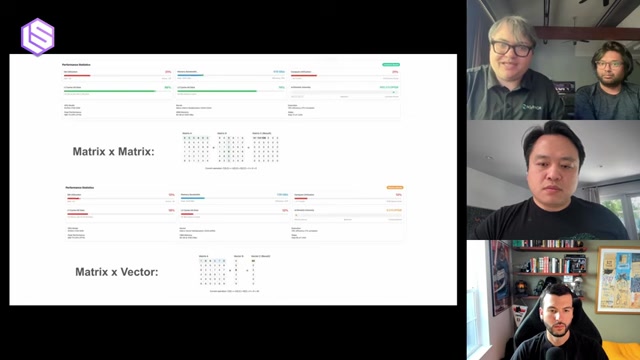
Thomas Sohmers: When it comes to memory accesses, with matrix-matrix multiplication, for every element in matrix B, you get to reuse the same element in matrix A. However, with matrix-vector multiplication, you need to change the elements in both matrix A and vector B for every single operation. This means matrix-vector multiplication is basically uncacheable. In Transformer inference, matrix A is the model weights. If you're talking about model weights that are tens or hundreds of gigabytes, you're not going to be fitting that in any on-chip cache. So, the memory architecture decisions of the past few decades go completely against what you need for this workload.
Fundamentally, what we're showing here with NVIDIA's A100 and H100 is that in their absolute best-case scenario for an H100 with Llama 70B, they're able to achieve about 29% of the theoretical memory bandwidth. You pay for 3.35 terabytes per second of memory bandwidth but in practice, you're only getting about a terabyte per second. The percentage of theoretical memory bandwidth has actually gotten worse generation over generation.
Positron's whole mission is about getting maximum memory bandwidth utilization. Our fundamental architecture is enabling us, with the hardware we're shipping today, to be achieving 93% of the theoretical memory bandwidth of our device, consistently across all use cases. This results in about 70% higher performance than NVIDIA with the cards we're shipping today, at significantly lower power and price points. And to re-emphasize, we are actually shipping.
Operational Achievements and Go-to-Market [00:16:53]

Mitesh Agarwal: The difference between us and other alternatives is that we got to market, shipping within 15 months of founding the company with only a seed round raised. We are now planning our next-generation silicon within 18 months of the first generation. So we are not only matching NVIDIA on performance but also coming up with new generations of the product at their pace. This is unlike many silicon and ASIC companies of the past decade that have taken three to five years to get a product out.
Swyx: That's an operational achievement. What's your secret?
Mitesh Agarwal: One is a small team. With a small team, you're forced to focus on the applications you want to ship out. For us, from day zero, it was about accelerating the linear algebra of matrix-vector math. Second, from a marketing term, we call it "falling within the NVIDIA ecosystem." From our past experiences, the biggest hurdle for new silicon providers has been convincing people to use it because there's always a change of workflow.
For us, we take the raw binary weights output from training on an NVIDIA GPU (like a .pt or .safetensors file) directly to our hardware. We can then output an OpenAI-compatible API. From a workflow perspective, you can have an NVIDIA server and a Positron server running side-by-side, and all you have to do is direct the tokens to whichever system you want without having to recompile the model for our system.
Thomas Sohmers: The key thing was that from the get-go, we knew that having even a single extra step for the user would be the ultimate barrier to adoption. We designed our hardware to directly ingest those raw binary model weights. We don't have a compiler or any tooling involved in taking those weights and getting them to execute on our device for common Hugging Face Transformer models. It's a zero-step process. We are betting that people are going to continue to train on NVIDIA for the foreseeable future. Since we're able to ingest the output of the CUDA infrastructure, we are in the CUDA ecosystem.
Power Efficiency and FPGA vs. ASIC [00:23:16]

Swyx: You're about a third of the normal power consumption. FPGAs are supposedly more power-hungry. How do you get there?
Mitesh Agarwal: We focus on both CAPEX (performance-per-dollar) and OPEX (performance-per-watt). That's why we focus on those two metrics.
Thomas Sohmers: It really depends on the application. If you're comparing an FPGA's power to a cell phone, then yes, the FPGA is a lot more power. But our cards are only using 150 watts. FPGAs are traditionally used for prototyping custom silicon, in HFT, and other areas. They are inefficient from a gate-count perspective, but everyone else has been focused on that 500-to-1000 FLOPS-per-byte world. They are so imbalanced that we can use an FPGA, which was not designed for this workload, and by implementing our unique architecture on it, we get these huge efficiencies because we're focused on that specific Transformer memory-bound use case.
Mitesh Agarwal: Relying on FPGAs was the way we got a product out so quickly. With our next generation, it's going to be a dedicated silicon where the inefficiencies of FPGAs, like brute-force specs on FLOPS and memory, will be improved upon. Our next-generation silicon will have the highest memory capacity by almost four to five times than any existing silicon at that point in time.
The Move to ASIC and Future-Proofing [00:29:03]
Alessio Fanelli: What's the penalty to go from FPGA to ASIC? What are you exactly burning on the ASIC, and what are you giving up by moving away from an FPGA model?
Thomas Sohmers: We are very opposed to the philosophy of burning the Transformer architecture into silicon. Fundamentally, what Positron has built is a linear algebra accelerator optimized for matrix-vector math, and more importantly, we achieve massive memory bandwidth to that pretty general compute architecture. I think it's foolish for anyone to say that Transformers are the thing that gets us to AGI or that there isn't a better architecture. Hardening for specific model things doesn't last more than two or three months at the rate the industry moves.
The thing I would be willing to bet the company on is that building a good linear algebra processor matters just as much in 2025 as it did in 1955 and as it will in 2055. Solving that as a core problem is what we've done. The software layers that enable you to get these models to run efficiently on that is a lot of our secret sauce, without hardening the hardware in a way that makes it too optimized for just what's hot right now.
Alessio Fanelli: Is there something that would make you change your mind? Something in maybe the model architectures?
Thomas Sohmers: I believe there are application use cases with high enough volume where a company can say, "We want to build this super-optimized chip that uses single-digit watts for just this one thing." I believe those applications can exist, but I've not seen something that would meet those criteria for me.
Mitesh Agarwal: There's a counter-example. Even the attention mechanism changing, which DeepSeek opened up to the world, if you had burned the architecture of doing Transformers the way before that, you might not be able to gain all those efficiencies. So that's a counter-example of why that is not the best approach.
On Competition and Market Dynamics [00:32:49]

Swyx: I don't know if you've seen the beef that George Hotz has had with Etched. Any comment there? Is he right?
Thomas Sohmers: George loves having beef with everyone. My opinion is it's a remarkably difficult thing to build any new silicon. I've met the Etched guys; they're cool guys, and I respect them for tackling a hard problem. I would disagree with the idea that you should be hardening in that way, and I'm skeptical of how much optimization you can even get without putting yourself in a restricted corner. But I'm looking forward to seeing what they develop. Success for any one of us is a success for all of us. Anyone that can take a little tiny chink in NVIDIA's armor is a great win for eventually having competition. The reality is NVIDIA is going to have a very, very good decade ahead of them, and the market is growing so fast that all of us can be very happy with very, very small wins.
Mitesh Agarwal: The markets are growing so massively that when certain inference applications come out, people will want to minimize costs. If our architecture is suitable for certain industries much more than NVIDIA's or AMD's, they would use us. In a way, it's expanding the market for those companies to be much more efficient.
The Importance of Revenue and Capital Efficiency [00:36:37]
Thomas Sohmers: The key thing that everyone should be looking at to measure success fundamentally comes down to revenue. You can announce the greatest piece of silicon, but the companies that are building the future applications will commit their dollars to the infrastructure providers that actually generate value for them. The biggest thing that everyone forgets when they hear a company has raised a huge amount of money is that raising money is one thing; being able to deliver real value to customers such that those customers are then paying you for that value is the only true measurement. I'm happy that we had our first revenue 15 months in, and we've deployed multiple rack-scale deployments.
Mitesh Agarwal: We have customers in Cloudflare and Perisale. Cloudflare, because of performance-per-watt, as they have data centers at the edge with limited power. Perisale is more focused on raw performance as an inference-as-a-service company. We've raised roughly $24 million publicly so far and just did a Series A close with Valor, Atreides, and DFJ Growth for a roughly $51 million Series A. That money is focused on our next-generation silicon. We want to prove this in a capital-efficient way. Ideally, we get the customers to pay for our production. We want to sell systems to customers.
Thomas Sohmers: The four most important letters are ROIC (Return on Invested Capital). From a customer's perspective, they're looking at it from an ROIC perspective. And from our side, we don't want to go and raise hundreds of millions of dollars. We raised as little as possible to minimize dilution because companies that raise huge amounts of money typically don't spend it very well.
Prefill vs. Decode Optimization [00:41:02]
Swyx: Is another way to phrase it that a lot of the other folks are focusing on prefill optimization, and you are just decode a lot faster?
Thomas Sohmers: Yes, our performance advantage is on that generation or decode side. For any Transformer LLM, you have the prompt that you're sending in. Computationally, that forward pass is exactly like the forward pass when you're doing training. Then when you switch into generation mode, you're generating one token at a time, and that is the memory-bound portion. We're still fully capable and perform well with prefill, but the thing that we believe in—and I was so happy last year when all the new reasoning applications happened—is that the ratio of input to output has completely flipped. If you look at benchmarks on these new models, you could be generating a hundred reasoning tokens for every token that you had as an input prefill.
The other big thing is our belief in having massive memory capacity. If you're able to just cache the KV caches, hold massive system prompts, and datasets that are typically recomputed every time you send in a new request, then that even makes the true prefill compute that you're doing significantly less.
The Shift to Autoregressive Models [00:43:46]

Thomas Sohmers: The other exciting thing to see over the past year has been that a lot of things have been moving away from diffusion to being pure autoregressive Transformers for image and video generation. For example, Sora V-JEPA and Imagen 3 from Google's side have been pure autoregressive, moving away from diffusion. The latest Athena model from xAI on the image generation side is a pure autoregressive Transformer. The ChatGPT image gen is also a pure autoregressive Transformer. All of those cases are now memory-bound.
When it comes to video, the rumor is that for eight seconds of V-JEPA image generation, it's around 800,000 to a million tokens. If you ballpark it at 100,000 tokens per second generated, the actual input prompt to that video model is hundreds of tokens, maybe. That ratio is just absurd when you get into modalities beyond text.
Call to Action: Hiring [00:45:35]
Alessio Fanelli: Any call to action? I'm assuming you're hiring. What type of people are you looking for?
Mitesh Agarwal: We are a small team of 27 people right now, heads down working on our next silicon. We're looking into hiring great verification engineers, design engineers, and silicon folks that have experience in 5nm, 7nm, and 3nm. We're also looking to build a well-rounded software engineering team to keep up with the multimodalities of different models.
Thomas Sohmers: We are a remote, distributed company with a few offices. We really want to bring in people that have no hardware experience but have been absorbed in the machine learning space, understand models, and want to take it to the next level of seeing how you can get the most efficiency and how better models can be created given new hardware.
Mitesh Agarwal: Someone looking at our architecture and thinking, "Actually, you know what, I can make a model architecture to be a lot better because I have all this memory capacity or all this memory bandwidth available to me."
Alessio Fanelli: Awesome, guys. Thanks for joining.
Mitesh Agarwal & Thomas Sohmers: Thank you so much for having us.